正则
正则的基础知识
什么是正则?
正则就是一个规则,用来处理字符串的规则
1、正则匹配
- 编写一个规则,验证某个字符串是否匹配这个规则,用test方法
2、正则捕获
- 编写一个规则,在一个字符串中,把符合规则的内容都获取到,使用方法:正则的exec方法、字符串中的split、replace、match等方法都支持正则
var reg=/^$/;//两个斜杠之间包含的内容就是正则,两个斜杠之间的全部内容都是元字符
正则的元字符和修饰符
任何一个正则都是由元字符和修饰符组成的
修饰符
- g(global):全局匹配
- i(ignore):忽略大小写匹配
- m(mutiline):多行匹配
元字符
[量词元字符]+:让前面的元字符出现1到多次?:出现0到1次*:出现0到多次{n}:出现n次{n,}:出现n到多次{n,m}:出现n到m次
[特殊意义的元字符]
-\:转义字符
-.:除了\n(换行符)以外的任意字符
-\d:匹配一个0-9的任意字符\D:匹配一个非0-9的任意字符\w:匹配一个[0-9a-zA-Z_]之间的任意字符\s:匹配一个任意空白符\b:匹配一个边界符(单词的左右,-的左右两边)x|y:匹配两者中的其中一个[a-z]:匹配a-z中的任意一个字符[^a-z]:匹配非a-z中的任意一个字符[xyz]:匹配xyz中的其中一个[^xyz]:匹配除了xyz以外的任意字符():正则小分组^:以某一个元字符开始$:以某一个元字符结束?: 只匹配不捕获?=:正向预查?!:负向预查
1 | var reg=/^\d$/; |
1 | var reg=/^18|19$/;// x|y的情况 |
()
- ()正则里的分组,大正则里的小分组,我们可以使用它
变默认的优先级 - 小分组还有第二个作用:
分组引用 - 小分组第三个作用:
分组捕获
分组引用:
\1表示出现和第1个分组一模一样的字符
1 | var reg=/^([a-z])([a-z])\2(a-z)$/;// 类似于food week feel oppo等都符合该正则 |
[ ]
[xyz] [^xyz] [^a-z]
var reg=/^[a-zA-Z0-9_]$/;//等同于\w
[ ]中出现的元字符,一般都代表本身的含义var reg=/^[.?+]$/里面的.代表.本身
//需求类的命名规则:数字字母下划线 _,(-不能作为开头)
var reg=/^\w[\w-]*$///不要让-出现在中间就可代表其本身的含义,出现在中间表示范围链接符
var reg=/^[18-65]$/代表的意思:1或86或5中的任意一个字符 ,中括号出现的18不代表数字18而是1或者8,当前正则非法19 (18|19)
18-65岁份三阶段
18
2059([2-5]\d)65(6[0-5])
60
验证是否为有效数字
可能正数,可能是负数
整数或小数
只要出现小数点,后面至少出现一位
小数点前必须有数字var reg=/^-?(\d|([1-9]\d+)(\.\d+)?$/
电话号码
1 | var reg=/^1\d{10}$/ |
中文姓名
1 | /^[\u4E00-\u9FA5]$/ :中文汉字的正则 |
邮箱
1 | reg=/^\w+((-\w+)|(\.\w+))*@[A-Za-z0-9]+((\.|-)[A-Za-z0-9]+)*\.[A-Za-z0-9]+$/ |
身份证号
1 | var reg=/^(\d{6})(\d{4})(\d{2})(\d{2})(\d{2})(\d)(X|\d)$/ |
正则捕获
把当前字符串中的符合规则的字符捕获到
RegExp.prototype.exec实现正则捕获的方法
当我们执行reg.exec(str)的时候,
- 1、先去验证当前字符串和正则是否匹配,如果不匹配则返回结果null;
- 2、如果匹配,从字符串最左边开始,向右查找匹配内容,并把匹配内容返回
exec捕获到的结果的格式:
获取的是一个数组
数组中的第一项是当前本次大正则匹配的结果
index:记录了本次捕获到结果的起始的索引
input:当前正则操作的原始字符串
如果当前正则当中有分组,获取的数组中,从第二项开始,都是每个小分组
执行一次exec只能把符合正则规则的一个内容捕捉到,若果还有其他符合规则的, 需要再次执行exec才有可能捕获到;
正则捕获的懒惰性
正则为什么会存在懒惰性
正则本身有一个属性:
lastIndex(下一次正则在字符串匹配查找时的开始索引)
默认值:0,从字符串的第一个字符开始查找匹配的内容
默认不管执行多少次exec,正则的lastIndex值都不会变,也就是还是从第一个字符开始查找
并且当我们手动改变last Index的值时,不会起任何作用
由此导致:执行一次exec捕获到第一个符合规定的内容,第二次执行exec,捕获到的依然是第一个匹配内容,后面的无论执行多少次都捕获不到
解决正则的懒惰性
在正则的末尾加修饰符g(全局匹配)
加了修饰符g,每次exec结束后,浏览器会默认把lastIndex的值进行修改,下一次从上一次结束的位置开始查找,所以可以得到后面匹配的内容了
1 | var reg=/\d+/g;//开启全局匹配 |
exec有自己的局限性,执行一次exec只能捕获到一个结果,如果想要全部捕获到,就要执行多次,下面封装的myExecAll方法,可以将正则匹配的全部内容捕获到
1 | RegExp.prototype.myExecAll=function(){ |
使用字符串中的match实现捕获
使用字符串match捕获,
- 如果正则加了g,会捕获到所有匹配结果
- 如果不加g,则只会捕获到第一个匹配结果
match的局限性
- 在加了修饰符g的情况下,·执行match只会把大正则匹配的结果捕获到,对于小分组里的匹配结果会自动忽略·
使用test实现捕获
不管是正则的匹配还是捕获,在处理的时候是没有区别的,从字符串里的第一个字符开始查找符合规则的字符,如果可以找到,则返回true,exec捕获返回捕获的内容,如果没有找到,test返回false,exec捕获返回null
如果正则设置了修饰符g,不管是使用test还是exec的任何方法,都会改变lastIndex值,(下一次查找是基于上一次匹配结果向后查找的)
1 | var str='my name is {0}~~';s |
test不仅可以找到匹配的内容,也肯能将匹配的内容获取
1 | console.log(RegExp.$1);//获取当前匹配内容的第1个小分组; |
所有支持正则的方法,都可以实现字符串的捕获(一般都是字符串方法)
字符串中常见的支持正则的方法
match **
*split *
var str=’name=”珠峰”&age=8’;
str.split(/(&|=)/); //使用split进行字符串进行拆分的时候,如果正则包含小分组,会把小分组的内容捕获到,放在最后的数组中
//本案例()只是为了改变优先级,但我们只想匹配不想捕获分组里的内容,?:可以解决
str.split(/?:(&|=)/);// 这样浏览器就不会把小分组的内容捕获到;要计算是第几个分组,从左到右数( =>半括号即可
**replace
字符串中原有字符的替换
str.replace(old,new)
1 | var str='珠峰2011珠峰1021'; |
在不使用正则的情况下,执行一次replace只能替换一个原有字符,第二次执行replace,依旧是从第一个字符开始查找,类似于正则的懒惰性
工作中,replace都是和正则一起搭配使用
replace原理:
- 当replace方法执行,第一项传递一个正则
- 正则不加g,把当前第一个字符串中和正则匹配的内容捕获到,替换成新字符
- 正则加g,把当前所有和正则匹配的内容都捕获到,并替换成新字符
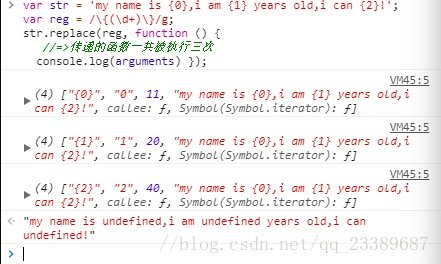
当replace执行,第二次参数传递的是一个函数(回调函数)
- 首先用正则在字符串中进行匹配,匹配到一个符合规则的,就把传递的函数执行一次
- 不仅执行这个函数,还把正则本次捕获的结果(同执行exec捕获的结果,包含小分组)当做实参传递给这个函数(这样就可以在函数中获得这些值,这些值就是正则每一次捕获的结果)
正则捕获方法统计
| 方法名 | 不加g | 加g |
|---|---|---|
| exec | 懒惰性,只能到捕获第一个匹配值包括小分组 | 多次捕获可得所有匹配字符,包括小分组 |
| match | 懒惰性 同上 | 一次捕获到所有匹配字符,但不能匹配到小分组 |
| test | 懒惰性同上 | 多次捕获可得全部内容,每执行一次test,就console.log(RegExp.$1),可得当前匹配字符 |
| replace | 懒惰性,只替换一个 | 全部替换 |
正则案例
=>单词首字母大写
1 | var str='my name is zhu-feng-pei-xun,i am 8 years old,i am qian duan pei xun no1!'; |
1 | var str='2017-11-07 16:30';//改写成2017年11月07日16时30分 |
模板匹配()
1 | var template='{0}年{1}月{2}日 {3}时{4}分{5}秒'; |
正则创建方式
字面量方式
1 | var reg=/\d+/img; |
构造函数创建
1 | new RegExp('元字符','修饰符') |
构造函数可以动态加入一个变量的值
问号传参(面试题)
1 | let url = 'http://item.taobao.com/item.htm?a=1&b=2&c=&d=xxx&e'; |

